

StopptUNSINN


Der am 20.07.2023 veröffentlichte Abschlussbericht des RKI zur StopptCOVID-Studie spart nicht mit Lob für unsere pandemischen Feudalherren: “Die in unserer Studie betrachteten NPI (nicht-pharmazeutische Maßnahmen) trugen wesentlich zur Bekämpfung der Pandemie bei und verhinderten in der Zeit bis zur Entwicklung wirksamer Impfstoffe eine starke Überlastung des Gesundheitssystems.” Man wird mit Behauptungen der Kausalität nahezu bombardiert, vor allem in der für Diagonalleser wichtigen “Zusammenfassung” am Anfang und “Diskussion der Ergebnisse” am Ende (Dekoration mit Ausrufezeichen durch mich):
Die in den verschiedenen Bereichen eingesetzten NPI führten zu einer Reduktion des R-Werts der Ausbreitung von SARS-CoV-2 in Deutschland!
In der Summe aller NPI führten Verschärfungen jeweils zu einer stärkeren Reduktion der COVID-19 Ausbreitung!
Eine hohe Impfquote hatte einen stark reduzierenden Effekt auf den R-Wert!
Die Verordnungen haben bereits vor ihrem Inkrafttreten einen Effekt auf die Ausbreitung der COVID-19-Epidemie in Deutschland ausgeübt!
Die Mainstreammedien haben diese Rechtfertigung des Irrsinns dankbar aufgesogen und sind ohne tiefergehende Betrachtung der Studie weitergezogen. Eine Gruppe von fünf Autoren hat sich eingehender mit dem Machwerk beschäftigt. Die Lektüre des zugehörigen ausführlichen Technischen Reports habe ich mir für die Zeit nach Veröffentlichung dieses Texts aufgehoben, damit ich nicht nur abschreibe, sondern meine Erkenntnisse gegen eine Messlatte halten kann.
Die RKI-Studie beschränkt sich auf den Zeitraum vom 01.03.2020 bis zum 31.08.2021 und versucht, die Entwicklung des R-Werts mit einem Modell zu erklären. Die Wahl des R-Werts als Zielgröße kann durchaus vernünftig sein, da er Inzidenzen in dicht beieinander liegenden (oder sich gar überschneidenden) Zeiträumen vergleicht und so weniger von Änderungen in der Teststrategie betroffen ist.
Gearbeitet wird auf Bundeslandebene. Zwar liegen Daten auf Kreisebene vor, diese werden aber fröhlich bis aufs Bundesland aggregiert - vermutlich auch eine gute Entscheidung, denn niemand sollte so vermessen sein, eine Pandemie auf Kreisebene erklären zu wollen. Leider ist mein Einblick beschränkt, denn die Daten liegen zwar im Schaufenster, aber als Privatperson habe ich keinen Zutritt.
Die Autoren arbeiten also letztlich mit 48 Zeitreihen (16 Bundesländer und drei Altersgruppen), die jeweils etwa 550 Datenpunkte aufweisen. Der tatsächliche Informationsgehalt beträgt aber nur ein Siebtel davon, da die Ausgangsgröße 7-Tages-Inzidenzen sind. Die Wahl der 4-Tages-Wachstumsrate (d.h. Ermittlung der R-Werte als Quotienten zweier 7-Tages-Inzidenzen, die 4 Tage auseinander liegen, sich also um drei Tage überschneiden), wird leider weder begründet noch einer Sensitivitätsanalyse unterzogen. Der ganze Spaß beruht also letztlich auf etwa 48 * 80 “echten” Werten.
Nun ist eine solche Datenbasis natürlich nicht nutzlos. Man kann sie gut verwenden, um einzelne Variablen dagegen zu halten und auf deren Erklärungsgehalt zu untersuchen. Genau das wird aber nicht getan: es wird eine Unmenge an Variablen deklariert (23 NPI, jeweils unterschieden nach Stufen, dazu Einfluss des Bundeslands, von Virusvarianten, Impfungen und Saisonalität sowie diverse mysteriöse “Berücksichtigungen”, beispielsweise von Schulferien und Feiertagen) und in einem Modell zusammengeführt.
Die mathematische Formulierung des Modells sieht dann so aus:
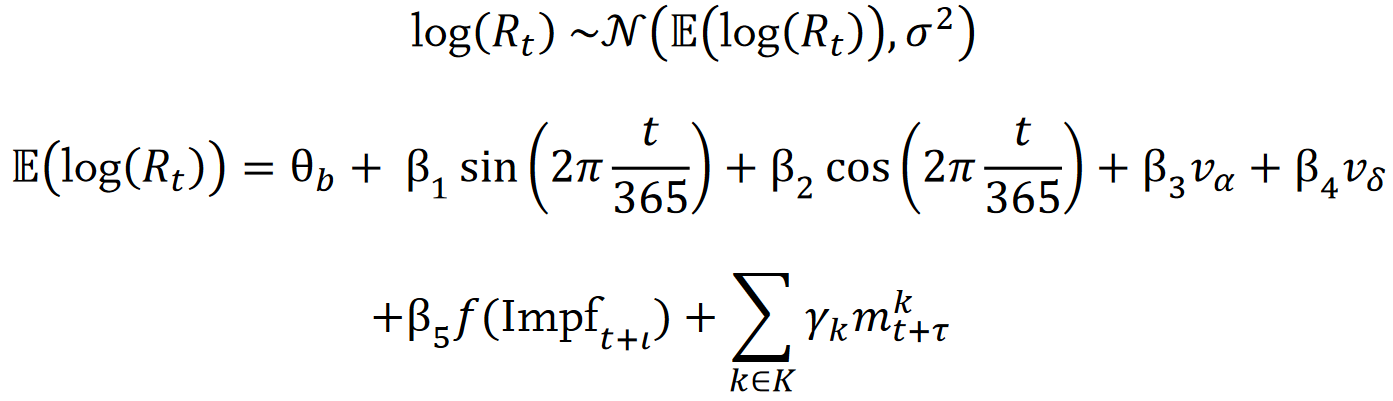
Der R-Wert zum Zeitpunkt t wird logarithmiert; das ist üblich, weil so multiplikative Effekte in additive überführt werden, was beim Rechnen angenehm ist. Die Formulierung sieht zwar auch eine Standardabweichung σ vor, diese wird aber leider hinfort ignoriert, und es wird nur der Erwartungswert geschätzt. Das bundeslandspezifische θb wird als Konstante bezeichnet und wurde scheinbar nicht geschätzt, sondern irgendwie von oben empfangen. Die Betas und Gammas hingegen sind die “zu schätzenden Koeffizienten” des Modells.
Aber halt! So einfach ist es mit der Schätzung dann wohl doch nicht. Insbesondere der Einfluss der Alpha-Variante (Koeffizient β3) und der Delta-Variante (Koeffizient β4) scheint delikat zu sein:
Da der Effekt der SARS-CoV-2 Varianten auf den R-Wert nicht ohne Weiteres von den Effekten der Impfung, den erweiterten Textkapazitäten [sic] ab dem Sommer 2020 und auch der im Verlauf der Pandemie weniger gut an die realen Maßnahmen angepasste Dokumentation abgegrenzt werden kann, betrachteten wir schließlich hauptsächlich ein Modell mit fixiertem Effekt der Varianten. Hierbei wurde festlegt, dass die Alpha-Variante zu einem 30% höheren R-Wert und die Delta-Variante zu einem 60% höheren R-Wert im Vergleich zum SARS-CoV-2 Wildtyp führt.
Ich habe keine Ahnung, was mit der “an die realen Maßnahmen angepassten Dokumentation” gemeint ist, aber in der “endgültigen” Formel wurde tatsächlich β3 durch 0.3 und β4 durch 0.6 ersetzt (und dann sinnloserweise β5 in β3 umbenannt, aber lassen wir das). Das führt aber nicht zu einem 30% bzw. 60% höheren R-Wert! Für den multiplikativen Effekt auf den R-Wert muss man nämlich das Logarithmieren rückgängig machen und bekommt exp(30%) - 1 ≈ 35% bzw. exp(30%) - 1 ≈ 82%, also noch einen größeren Effekt.
Wie wurden die 30% bzw. 60% denn nun bestimmt? Es ist nicht überliefert, aber ich habe eine Vermutung. Auf Seite 33 wird von einem R-Wert des “Wildtyps” zwischen 2.8 und 3.8 gesprochen. Wenn man nun unbedingt annehmen möchte, dass Alpha einen höheren R-Wert als der “Wildtyp” hat, dann kann man die untere Schranke für den R-Wert von Alpha auf die obere Schranke für den R-Wert des “Wildtyps” setzen. Tatsächlich ist log(3.8 / 2.8) ≈ 30.5%. Wenn man nun weiter die obere Schranke für den “Wildtyp” mit dem Faktor 3.8 / 2.8 skaliert, kommt man auf 3.8 * 3.8 / 2.8 ≈ 5.16. Und wenn nun wieder Delta schlimmer als Alpha sein soll, nimmt man dies als untere Schranke für den R-Wert von Delta. Und tatsächlich: log(5.16 / 2.8) ≈ 61%.
Wie dem auch sei. Im Anschluss an die Darstellung des Formelwerks werden viele bunte Diagramme präsentiert, aber eigentlich ist es aufschlussreicher, was wir nicht zu sehen bekommen.
Wir bekommen nie einen modellierten R-Wert zu Gesicht. Die einzigen Bilder mit R-Werten sind auf den Seiten 12 und 13 zu finden, und sie zeigen die empirischen Daten. Danach werden immer (S. 23, 24, 25, 28, 29) nur Inzidenzen gezeigt, und auch nur die empirischen. Wie würde die Zeitreihe des modellierten R-Werts aussehen (bitte mit Konfidenzintervallen), und wie die Zeitreihe der aus den modellierten R-Werten zurückgerechneten Inzidenzen (bitte ebenfalls mit Konfidenzintervallen)? Wahrscheinlich würden wir aus dem Lachen nicht mehr herauskommen, was natürlich der Gesundheit abträglich sein könnte und daher vom RKI nicht verantwortet werden konnte.
Wir bekommen auch nie eine Prognose des Modells, beispielsweise für den Zeitraum nach dem 31.08.2021, zu Gesicht. Hier noch mal die guten alten Inzidenzen (nach RKI-Daten; gemittelt über die beitragenden 5-Jahres-Altersstufen; leicht abweichend von der Darstellung im Bericht):
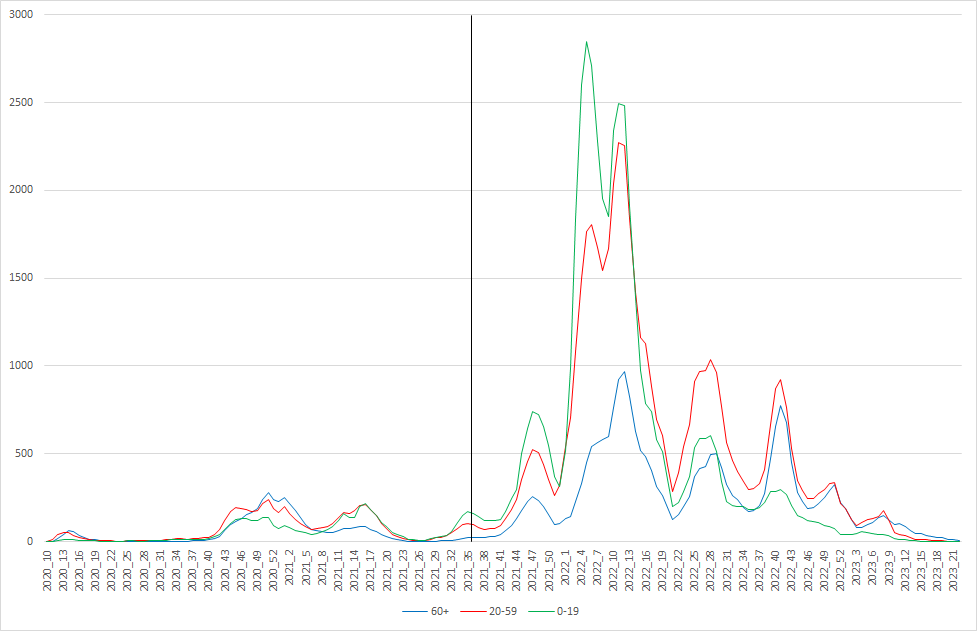
Der Bericht kennt nur den Zeitraum links von der schwarzen Linie. Ob das Modell wohl die Entwicklung rechts von der Linie prognostizieren könnte? Oder wie wäre es mit den R-Werten (hier immer ermittelt als Quotient der Inzidenzen in den aufeinanderfolgenden Wochen):
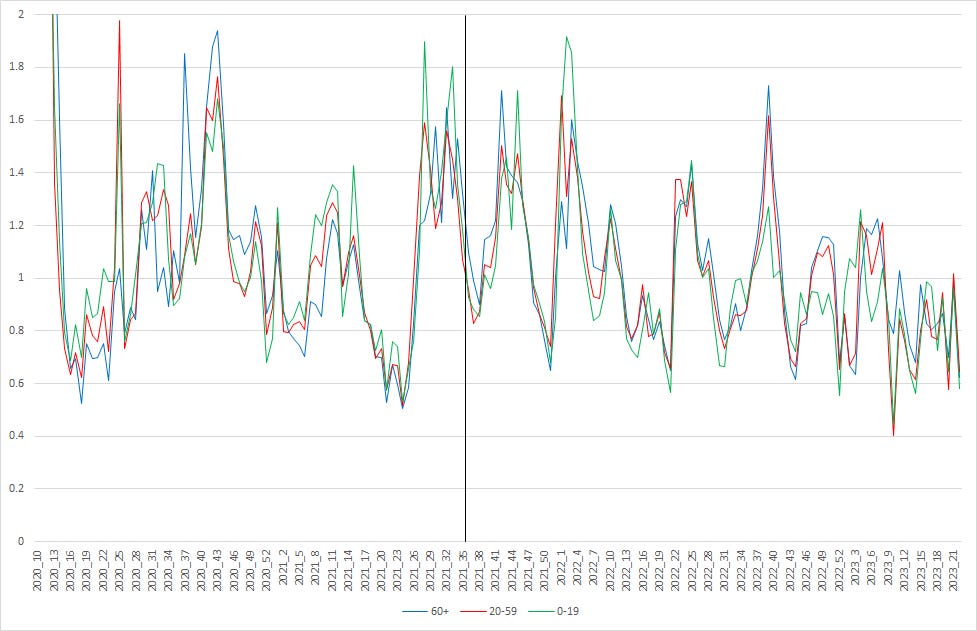
Auch mit den hohen Inzidenzen sind die R-Werte rechts von der schwarzen Linie nicht höher als links davon (wenn auch für längere Zeiträume größer als Eins, was zu den hohen Inzidenzen führt) - und das trotz Übergang auf Omikron und kontinuierlichem Zurückfahren der Maßnahmen. Kausalität, wo bist Du?
Auf die angeblichen Effekte der Maßnahmen will ich gar nicht im Detail eingehen, sondern mir nur die ach so segensreiche Impfung herauspicken. Stellt man den unteren Teil von Abb. 10 (Impfquoten der Über-60-Jährigen) einmal Abb. 13 (Anteile von “Wildtyp”, Alpha und Delta) gegenüber, so bekommt man das folgende Bild:
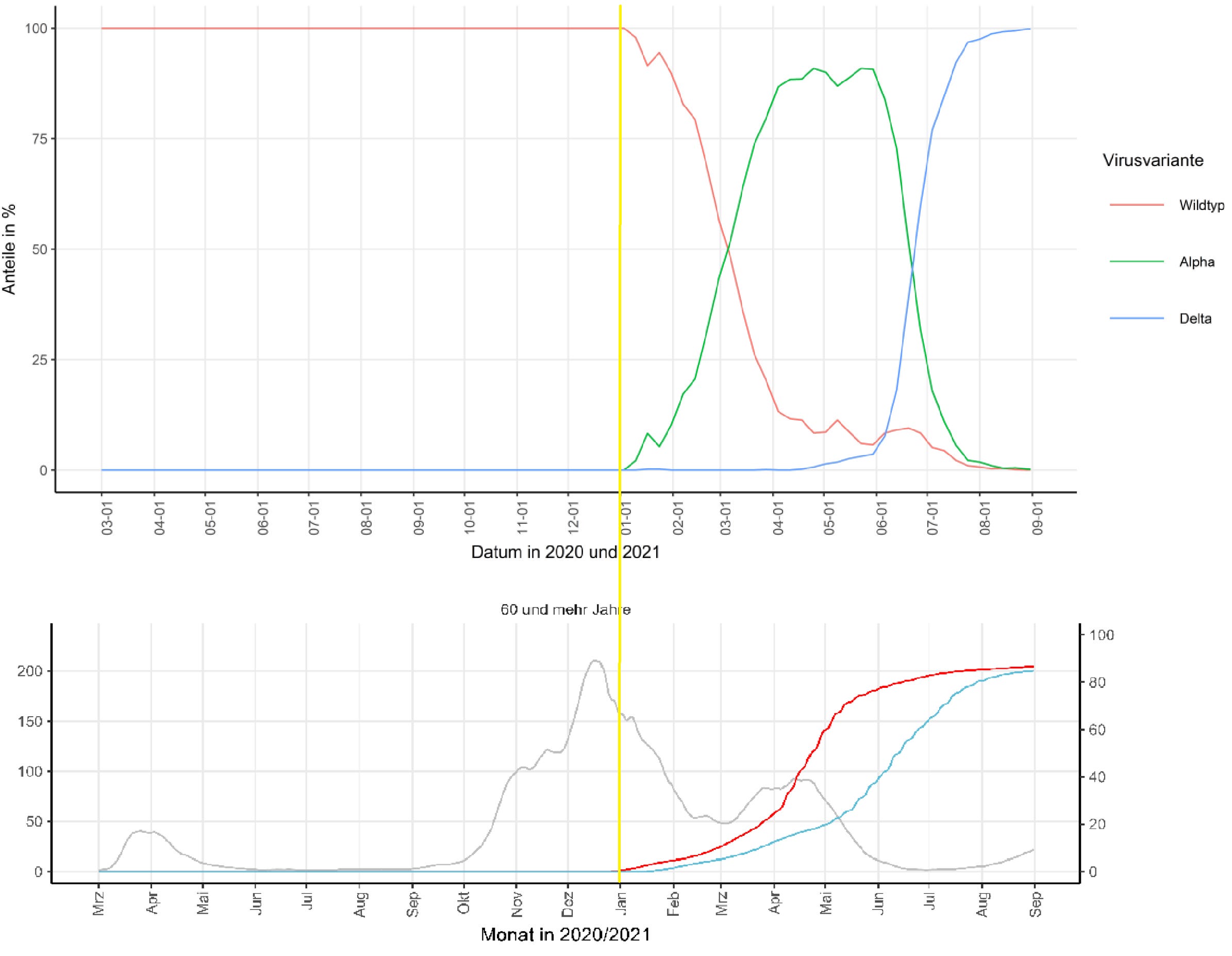
In diesem Modell, mit seinen Koeffizienten 30% für Alpha und 60% für Delta, kann gar nichts anderes als ein scheinbar R-Wert-reduzierender Effekt der Impfung herauskommen. Können wir das Modell bitte noch einmal unter der Annahme laufen lassen, dass der “Wildtyp”, Alpha und Delta alle gleich infektiös sind? Oder können wir bei der Gelegenheit in Abb. 2 (“mögliche kausale Einwirkungen”) sicherheitshalber auch mal Pfeile von “Vaccination” zu “Variant” malen? Welche Bedeutung hat ohnehin der R-Wert (Angeblich hat sich Herr an der Heiden damit ja beschäftigt)? Was habe ich mir unter dem “eigentlichen” R-Wert von 2.8 bis 3.8 für den Wildtyp (und 5.1 bis 6.9 für Delta) vorzustellen? Unter welchen Bedingungen würde dieser in der Praxis erreicht, und für wie lange? Warum geht der reale R-Wert nie über einen Wert von zwei hinaus, selbst zu maßnahmenfreien Zeiten? Was taugen eigentlich die epidemischen Modelle, die die Epidemiologen so epidemisch züchten?
Liebes RKI, das war ja mal gar nichts. Euer Modell kann wirklich überhaupt keine kausalen Aussagen treffen; es zaubert Schätzungen unzähliger Parameter quasi aus dem Nichts; und es verschwendet mein Steuergeld. Schade.
Tolle Kritik, Danke! Die RKI sind einfach nicht mehr ernst zu nehmen, oder?
Was für Ein eine Blamage:D